- Hasura Platform
- Getting started
- Installing the Hasura CLI
- The complete tutorial
- GraphQL tutorial
- Hasura project
- Hasura cluster
- Project microservices
- API Console
- Auth
- Data (GraphQL/JSON APIs)
- Filestore
- Notify (Sending emails/SMS)
- Postgres
- API gateway
- Hasura Hub
- Hasura CLI reference
- Hasura API reference
- Guides
- Installing Hasura on a Kubernetes Cluster
- Hasura architecture
- Billing for Hasura
- Moving to v0.16 from v0.15
- Moving to v0.15 from older versions
Hasura architecture¶
Note
This is an advanced guide to the internals of Hasura. If you’re an advanced user or know Kubernetes details you can go ahead and read this. Please note you do not need to know this to use Hasura.
The Hasura platform is a set of kubernetes resources. A controller initialises, manages and updates these resources. This controller keeps track of project configuration changes and applies them to dependent resources as required.
Shukra: The kubernetes controller¶
The main intelligence and work of managing a Hasura project is done by a special kind of microservice, typically referred to in the Kubernetes community as a controller or an operator.
Shukra is a microservice that connects to the kubernetes API server and manages state, and other kubernetes resources that together represent the Hasura platform. Shukra is not a web/API microservice; it is an active reconciliation process. It watches some object [project-configuration] for the world’s desired state, and it watches the world’s actual state too. Then, it sends instructions to try and make the world’s current state be more like the desired state.
shukra can be run with 2 arguments:
shukra -c controller-conf.json init: Shukra initialises the platform state and exitsshukra -c controller-conf.json sync: Shukra runs as an active process continuously syncing configuration changes to the kubernetes cluster. sync can only be run after a successful init.
Note
In sync mode, shukra runs as a kubernetes deployment. You can fetch information regarding shukra (eg: logs) by:
kubectl -n hasura get deployment shukra
Kubernetes lifecycle of a Hasura project¶
The easiest way to understand what a Hasura project looks like from the kubernetes point of view is to understand how a Hasura project is initialised and how it runs on a Kubernetes cluster.

2. Adding the hasura namespace¶
Second, we create a hasura namespace where the Hasura platform services will live:

3. Specifying the initial configuration¶
Two important pieces of information are required to initialise a Hasura project:
- Controller configuration: This specifies infrastructure level information for the Hasura controller (external IP, kubernetes API server information etc.)
- Project configuration: This specifies the application level configuration (auth API configuration, domains/routes on the gateway etc.)
These are added as configmaps and secrets to the default namespace:
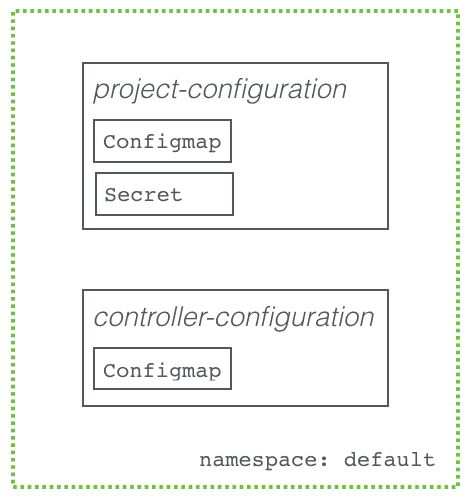
4. Initialising the hasura platform state: controller init¶
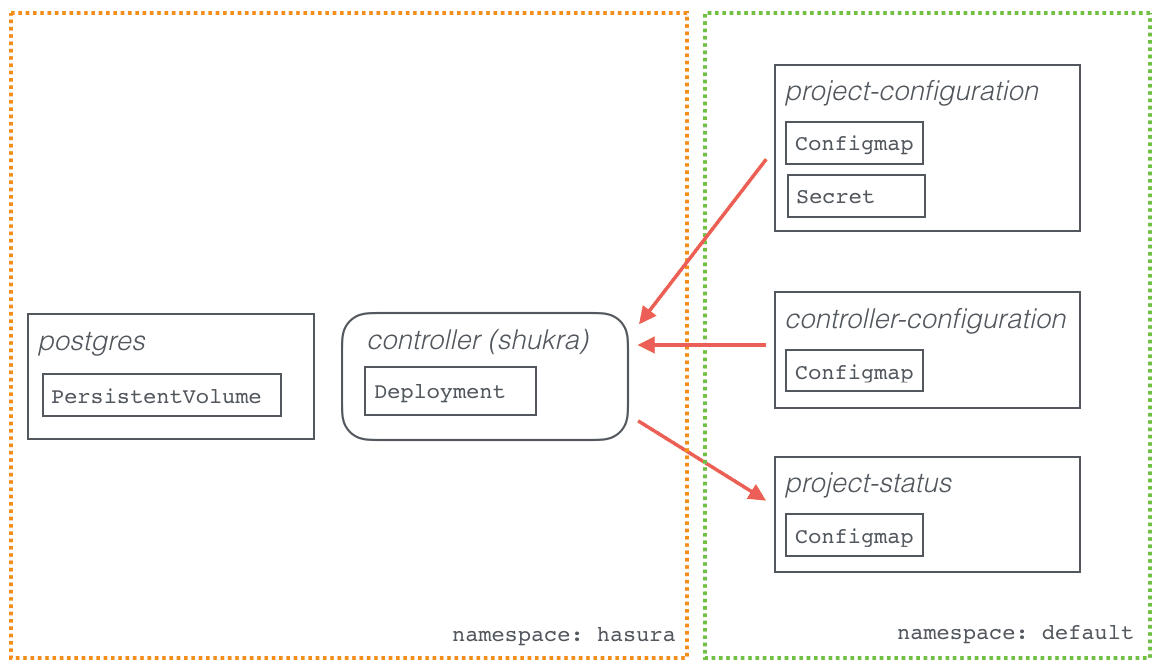
To initialise the Hasura platform, some state needs to be initialised (eg: create database schemas, create the superadmin user etc.)
The init command by the Hasura controller (codenamed: shukra)
does the following:
- Initialises the postgres database server
- Runs migrations for the hasura data, auth and filestore API microservices
- Creates the superadmin user/password
The Hasura controller reports its progress and logs warnings/errors in
a configmap called hasura-project-status.
This is what the kubernetes cluster would look like after a successful
init:
5. Deploying the hasura platform: controller sync¶
To deploy the Hasura platform, the controller deployment is created and runs with the sync command.
The sync command by the Hasura controller does the following:
- Watches the project-configuration (configmap & secret) for changes
- Creates/updates kubernetes resources like deployments/services/configmaps according to those changes
The Hasura controller reports its progress and logs warnings/errors in
a configmap called hasura-project-status.
This is what the kubernetes cluster would look like after a successful
sync:
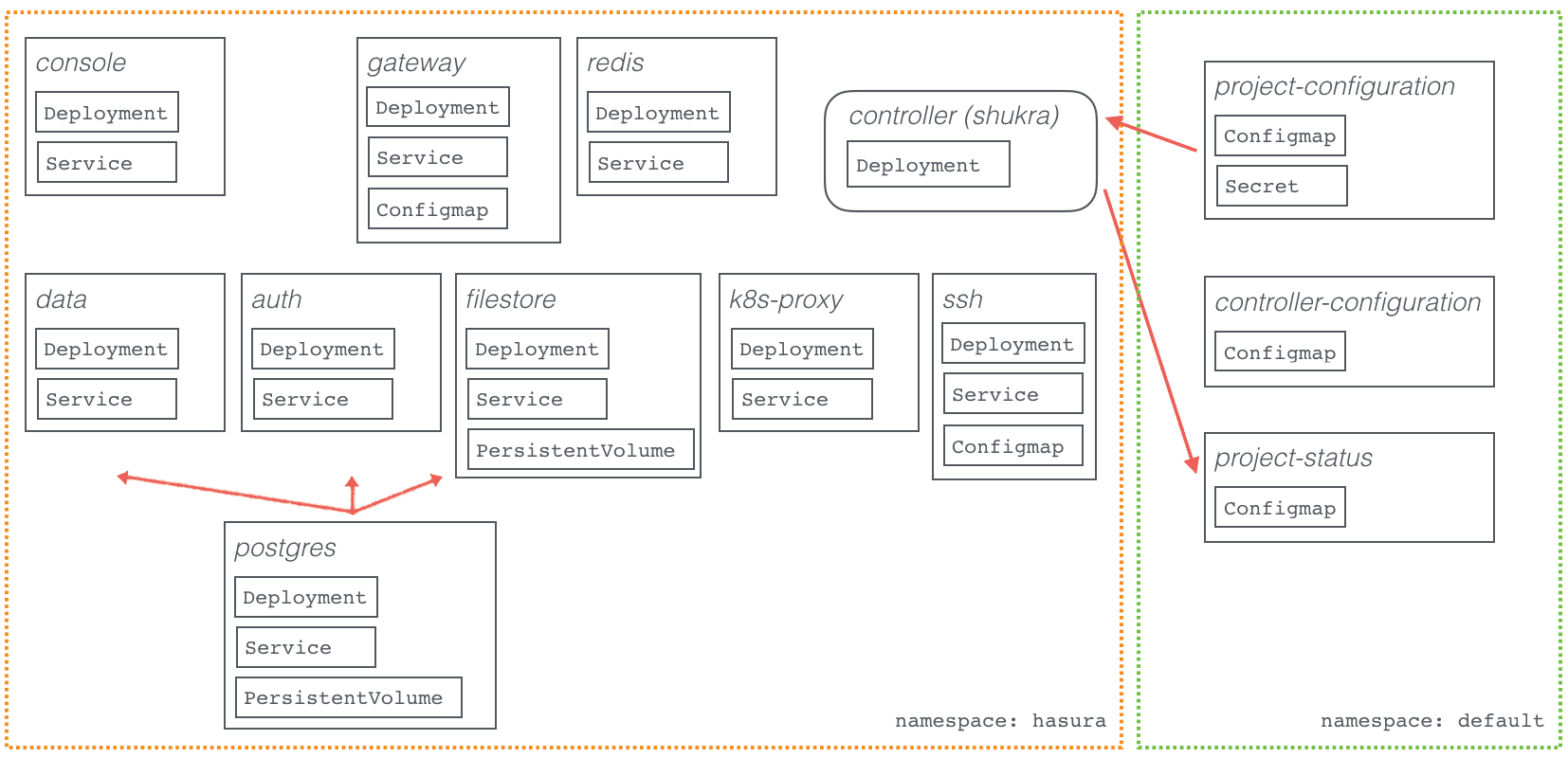
It is important to note, that the data, auth & filestore APIs depend on the postgres server to initialise and maintain their state. Additionally, the filestore API microservice also depends on a persistent-volume to store its data (files).
